推荐系统 - 召回
01 离散特征处理
1.1 什么是离散特征?
- 性别: 男、女两种类别
- 国籍: 中国、美国、印度等 200 个国家
- 英文单词: 常见的英文单词有几万个
- 物品 ID: 小红书有几亿篇笔记,每篇笔记有一个 ID
- 用户 ID: 小红书有几亿个用户,每个用户有一个 ID
1.2 离散特征处理

1.3 One-Hot Encoding 编码


One-Hot 编码的局限
- 例1: 自然语言处理中,对单词做编码
- 英文有几万个常见单词
- 那么 one-hot 向量的维度是几万
- 实践中一般不会用这么高纬的向量
- 例2: 推荐系统中,对 物品ID 做编码
- 小红书有几亿篇笔记
- 那么 one-hot 向量的维度是几亿
类别数量太大时,通常不用 one-hot 编码
1.4 Embedding 嵌入
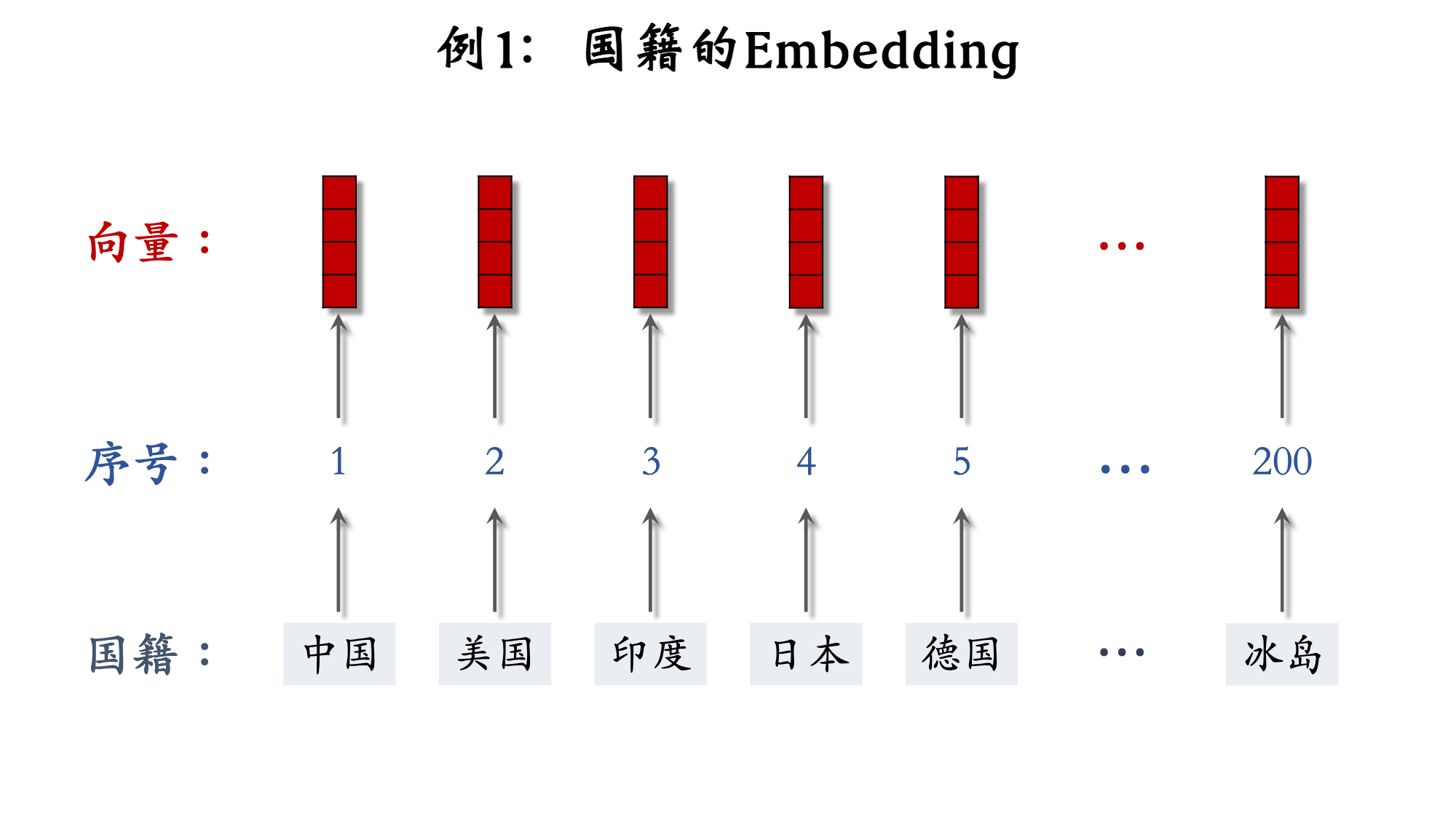
- 参数数:
向量维度 × 类别数量- 设 embedding 得到的向量都是 4 维的
- 一共有 200 个国籍
- 参数数量 = 4 × 200 = 800
- 编程实现: TensorFlow, PyTorch 提供 embedding 层
- 参数以矩阵的形式保存,矩阵大小是
向量维度 × 类别数量 - 输入是序号,比如"美国"的序号是 2
- 输出是向量,比如"美国"对应参数矩阵的第 2 列
- 参数以矩阵的形式保存,矩阵大小是
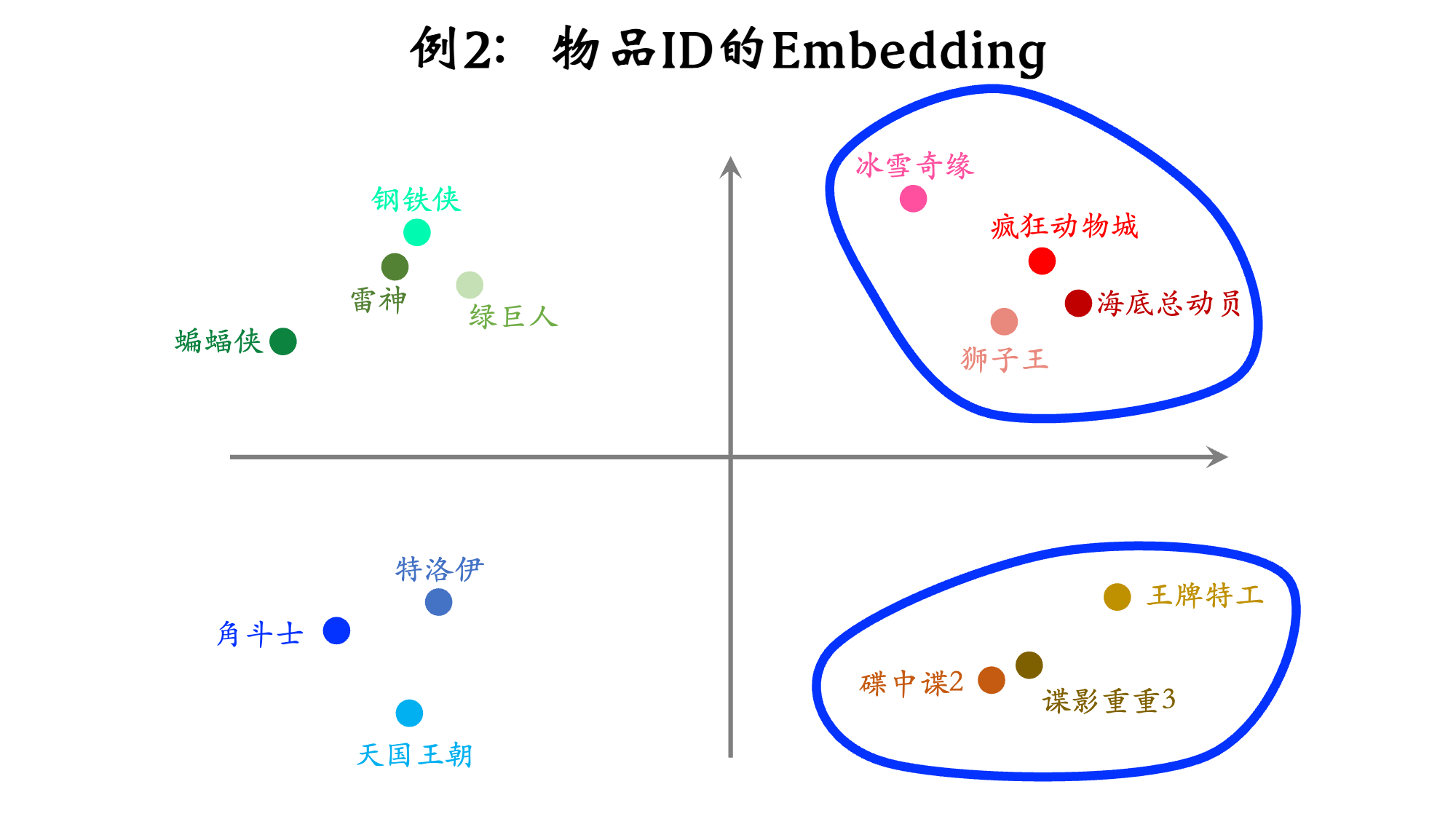
- 数据库里一共有 10,000 部电影
- 任务是给用户推荐电影
- 设 embedding 向量的维度是 16
- Embedding 层有多少参数?
参数数量 = $向量维度 × 类别数量 = 160,000